
Stable Code 3B: Coding on the Edge
Key Takeaways:
Stable Code 3B is a 3 billion parameter Large Language Model (LLM), allowing accurate and responsive code completion at a level on par with models such as CodeLLaMA 7b that are 2.5x larger.
Operates offline even without a GPU on common laptops such as a MacBook Air.

Today, we announce our first Large Language Model release of 2024: Stable Code 3B. This new LLM is a follow-up to our previously released Stable Code Alpha 3B and the first major Stable Code release, offering a new state-of-the-art model designed for code completion with multiple additional capabilities.
Compared to CodeLLaMA 7b, Stable Code 3B is 60% smaller while featuring a similar high-level performance across programming languages. Based on our pre-existing Stable LM 3B foundational model trained on 4 trillion tokens of natural language data, Stable Code was further trained on software engineering-specific data, including code. The model's compact size allows it to be run privately on the edge in real-time on modern laptops, even those without a dedicated GPU.
Stable Code 3B offers more features and significantly better performance across multiple languages with additional benefits such as support for Fill in the Middle capabilities (FIM) and expanded context size. Stable Code as a base is trained on sequences of up to 16,384 tokens but follows a similar approach to CodeLlama with the implementation of Rotary Embeddings, optionally allowing modification of the rotary base up to 1,000,000, further expanding the model’s context length up to 100k tokens.
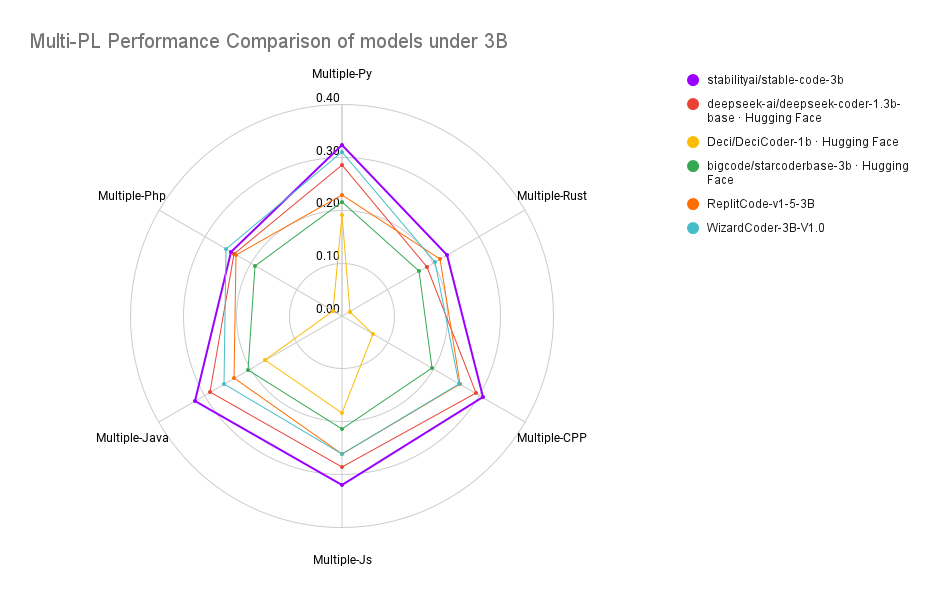
Stable Code is trained on 18 programming languages (selected based on the 2023 StackOverflow Developer Survey) and demonstrates state-of-the-art performance (compared to models of similar size) on the MultiPL-E metrics across multiple programming languages tested.
Performance Comparison

Side by Side Comparison of Stable Code Completion 3B with CodeLLama 7B

Training Insights
Our training pipeline consists of a multi-stage process similar to Codellama. We start with an LM pre-trained on natural language data, in this case, StableLM-3B-4e1t, followed up with unsupervised fine-tuning on multiple code and code-related datasets, including CommitPack, GitHub Issues, StarCoder & other Math datasets. In the second step, we further fine-tune the model with longer sequences of 16,384 tokens with the base modification suggested in CodeLLama. The new stable-code model also supports Flash Attention 2 and is available for use.
Further references to the data and model can be found in our model card. We will release a full technical report with additional details and ablations to be more transparent and open to the community.
Commercial Applications
This model is included in our new Stability AI Membership. Visit our Membership page to take advantage of our commercial Core Model offerings, including SDXL Turbo & Stable Video Diffusion.
Stay updated on our progress by signing up for our newsletter, and learn more about commercial applications by contacting us here.
Follow us on Twitter, Instagram, LinkedIn, and join our Discord Community.